ReSpace: Text-Driven 3D Indoor Scene Synthesis and Editing with Preference Alignment
Stanford University




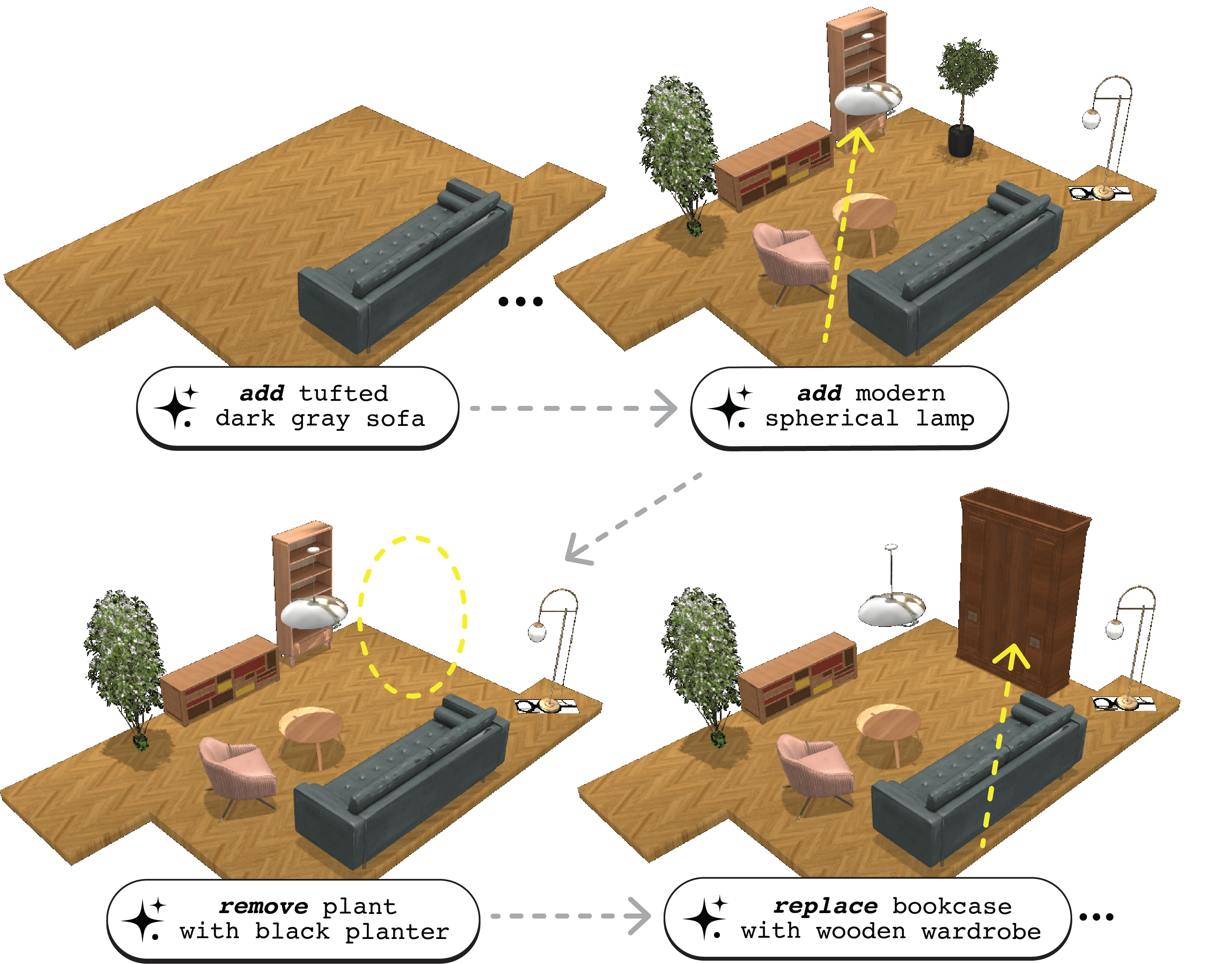
Scene synthesis and editing has emerged as a promising direction in computer graphics. Current trained approaches for 3D indoor scenes either oversimplify object semantics through one-hot class encodings (e.g., 'chair' or 'table'), require masked diffusion for editing, ignore room boundaries, or rely on floor plan renderings that fail to capture complex layouts. LLM-based methods enable richer semantics via natural language (e.g., `modern studio with light wood furniture'), but lack editing functionality, are limited to rectangular layouts, or rely on weak spatial reasoning from implicit world models. We introduce ReSpace, a generative framework for text-driven 3D indoor scene synthesis and editing using autoregressive language models. Our approach features a compact structured scene representation with explicit room boundaries that enables asset-agnostic deployment and frames scene editing as a next-token prediction task. We leverage a dual-stage training approach combining supervised fine-tuning and preference alignment, enabling a specially trained language model for object addition that accounts for user instructions, spatial geometry, object semantics, and scene-level composition. For scene editing, we employ a zero-shot LLM to handle object removal and prompts for addition. We further introduce a voxelization-based evaluation capturing fine-grained geometry beyond 3D bounding boxes. Experimental results surpass state-of-the-art on addition and achieve superior human-perceived quality on full scene synthesis.


Prompt List (8): “plush cushions bed”, “gray minimalist nightstand”, “traditional three-door wardrobe”, “dual-tone table”, “decorative padded beige seat chair”, “white planter”, “wooden and metal bookcase”, “modern lamp”
Prompt List (11): “modern brown leather sofa”, “grey corner table with crossbar”, “low-profile floor lamp”, “simple white coffee table”, “blue velvet armchair”, “wooden wall art”, “classic pendant lamp”, “low storage cabinet”, “mid-century wooden side table”, “tv stand”, “hanging plant”

@article{bucher2025respace,
title={ReSpace: Text-Driven 3D Indoor Scene Synthesis and Editing with Preference Alignment},
author={Bucher, Martin JJ and Armeni, Iro},
journal={arXiv preprint arXiv:2506.02459},
year={2025}
}